
在事实核查流程结束后,包括有据在内的大部分事实核查机构会针对被核查的说法得出一个判断性的结论,比如“虚假”、“真实”和“误导”等等。
全球事实核查评级系统的分类
就全球范围而言,总的来说,大部分事实核查组织和有据一样,都会使用评级系统,大致分为四类:
第一类使用文本,基于一组表示真实性的词语,比如:真实、大部分真实、误导、大部分虚假、虚假等。
第二类使用图像,基于一系列表示真实性程度的图标或者图像,比如《华盛顿邮报》的匹诺曹、PolitiFact的Truth-O-Meter评级系统。
第三类使用颜色,基于一系列从红色到绿色的颜色编码来表示不同级别的真实性,比如哥伦比亚事实核查组织ColombiaCheck:红色=假、橙色=误导、绿色=真实。

第四类使用数字,给核查内容打分,比如,1-5或1-10等。
不过,也有核查机构不使用评级系统,比如英国事实核查机构Full Fact。在Full Fact的核查文章中,也会针对核查内容作出评判,但不会依据一个固定的评级系统。
Full Fact拒绝使用评级系统的理由是:
“我们认为,在某些情况下,这样的评级可能过度简化,并不总是能完全传达我们核查结果的细微差别。通常的情况是,一项主张既不是简单的真也不是简单的假,而是缺少重要的背景。
Full Fact一直在寻求一种不具对抗性、更具协作性的事实核查方法。我们的使命是确保公众能够获得尽可能好的信息。我们努力与决策者和舆论塑造者合作,并对他们进行事实核查,以最好地服务我们的读者。”
有据的评级系统
有据目前沿用的评级系统是:
虚假:根据目前公开的最佳证据,这种说法是不准确的。
真实:根据目前公开的最佳证据,这一说法是准确的,而且没有遗漏任何重要的内容。
误导:信息片面、过期、挪用,或者标题党等等,导致受众产生错误的理解。
大部分虚假:根据目前公开的最佳证据,该说法的主要部分是虚假的,尽管有微小的部分是真实的。
大部分真实:该说法包含真实要素,但根据目前公开的最佳证据,要么不完全准确,要么需要澄清。
部分虚假:说法中包含一些真实的信息,但也包含虚假的内容。
无法证实:目前公开的证据既不能证明也不能证伪这一说法,需要更多的研究。
使用评级系统的得与失
有据使用这种评级系统的初衷是,对读者来说,它可以使核查文章更清晰和直接。不是每个人都有耐心阅读整篇事实核查,更多的人会首先注意到一个结论或者图标,直接告诉他们某些说法是真的还是假的。
其次,使用评级系统可能是事实核查这种新闻形式的特点,也是受众对于事实核查的期待,他们渴望负责任的事实核查机构能够作出明确的判断,而不是列出大量的数据和证据,却把作出判断的责任交给读者。
同时,对于事实核查机构来说,使用评级有助于建立品牌识别度,因为通常情况下,事实核查操作中最容易识别的元素是其评级系统,有特点的图标和结论、标题的文本等,很容易在社交媒体上分享。
也就是说,我们本来认为评级只是对我们所得出结论的简单易懂的总结,类似评论家对电影或餐馆的评级,是引诱读者阅读更长、更细致的核查的入口。
但是,在实践中,我们也感受到评级系统带来的局限性。
一些事实核查可能难以符合现有的任何一个评级的标准。同时,另一些事实核查可能又符合现有的多个评级标准。而且,在一些极偶然的案例中,随着时间的推移,我们发现可能会逐渐改变最初的评级判断。
一些标准很难科学衡量,比如“大部分虚假”和“部分虚假”之间无法用简单的定量标准来区别;65%是假的跟35%是真的之间到底有什么差别?可能大多数读者不关心或没有时间关心这样的区别,他们可能只是想知道他们在网上看到的内容是真是假。
我们有时候发现,即使每个事实核查员都严格遵循我们的方法论,但在数百次事实核查中很难一直保持一致性。而如果不同的事实核查员给出不同的评级,读者可能会感到困惑,不确定该相信什么。而且,有些读者会认为评级是我们对事实进行了自己的主观解释。
如果核查的说法包含多个不同的核查点,而事实核查员将它们捆绑在一起,提供一个单一的评级(例如“部分虚假”),那么读者可能会认为所有这些点都是部分虚假的,即使其中一些完全是假的,而其他的是真的。
从操作层面看,使用评级系统会给编辑过程增加大量工作,因为有时候会消耗大量时间讨论到底应该作出怎样的结论,而在不评级的情况下发布核查结果肯定会更简单。
而且,有时候读者会发现,对同一则传言,不同的事实核查机构可能有不同的评级结果,尽管它们的核查方式和证据几乎是一样的。这种相互矛盾可能会让读者更加困惑,甚至让它们对事实核查失去信心。
因此,有据对评级系统的使用经历了一个变化升级的过程,在后期的核查实践中,删除了一些评级类别,比如“片面”和“过期”,更审慎使用“部分虚假”、“大部分虚假”、“部分真实”等评级标签,增加了“误导”标签的使用频率,在使用“误导”标签时会更清晰地解释原因。
争议案例1:
2022年1月初,#美国宇航员为返回地球制造事故#登上微博热搜。有关内容称:“当地时间12月31日,俄罗斯国家航天集团表示,两名在轨的俄罗斯宇航员发现了国际空间站星辰号服务舱的最后一处漏气点。而调查显示,这起事故是一名美国宇航员故意为之,为的是引发事故以便能早日返回地球。”

针对这一说法,核查员首先梳理了泄漏事故的背景:
2018年6月6日11时12分,俄罗斯联盟MS-09飞船从哈萨克斯坦拜科努尔航天发射场发射升空,这是联盟号的第138次飞行,本次任务将“远征56”的三名宇航员——美国宇航局(NASA)的Serina Maria Auñón-Chancellor(塞里纳·玛丽亚·奥尼翁-钱赛乐)、欧洲航天局宇航员Alexander Gerst(亚历山大·格斯特)和俄罗斯宇航员Sergey Prokopyev(谢尔盖·普罗科佩耶夫)送到国际空间站。

2018年8月29日,位于休斯顿的美国宇航局约翰逊航天中心的国际空间站控制人员注意到空间站的压力略有下降。第二天,他们通知了空间站的宇航员,宇航员发现俄罗斯联盟号MS-09飞船上有一个2毫米的孔,如果不加以控制,这个小洞会在大约两周内使空间站减压。

随后,宇航员对该孔用Kapton胶带和环氧树脂进行了修补。美国宇航局官员强调,机组人员从未处于任何危险之中。宇航员在后来的舱外活动中确认先前漏气的孔位于轨道舱,对返回地球没有影响。联盟MS-09飞船于2018年12月20日5时22分按照预定计划成功着陆地球。
在了解清楚事件背景后,核查员从公开信息中搜集了有关这次事件的调查进展。因为事件主要涉及俄罗斯和美国,所以我们尽量搜集了来自双方的信息。不过,基于当时的信息,来自俄方的指控居多,美方则予以否认,来自第三方的材料和证据较少:
事发后,2018年9月,俄罗斯《生意人报》发表文章称,俄罗斯调查人员正在大力追查美国人可能故意损坏联盟号飞船的说法。
2019年,俄罗斯国家航天集团公司(Roscosmos)总裁德米特里·罗戈津 (Dmitry Rogozin) 对俄罗斯媒体说: “我们正在考虑所有理论。关于陨石撞击的理论已被否定。它似乎是由一只摇摇晃晃的手完成的……它是由人手完成的,有钻头沿着表面滑动的痕迹。”
俄罗斯官员进一步暗示,“不稳定的手”很可能是由于在微重力下钻探的罪魁祸首,这意味着其中一名机组人员应该受到指责——而不是在发射到地球之前参与联盟号飞船组装和测试的俄罗斯工程师。
2021年8月12日,俄罗斯塔斯社发表文章指责NASA宇航员Serina Maria Auñón-Chancellor在太空中情绪崩溃,然后损坏了停靠在空间站的俄罗斯联盟号宇宙飞船,以便她可以早日返回地球。

塔斯社记者米哈伊尔·科托夫(Mikhail Kotov)采访了俄罗斯国家航天集团公司的一位匿名官员。他写道:“女宇航员的疾病,这是第一个已知的在轨深静脉血栓事件,而且Serina Maria Auñon-Chancellor患有这种疾病的事实是在她返回地球后才发表在一篇科学文章中。据我的匿名消息来源称,这可能引发了’严重的心理危机’,并导致她通过各种手段试图加快她返回地球的速度。 ”
Auñón-Chancellor在正常返回地球后接受了治疗,因为她颈部的颈静脉出现深静脉血栓。美国专业航天网站space.com称,NASA通常会将所有宇航员的医疗记录和条件保密。
针对塔斯社的文章以及对Auñón-Chancellor的指控,2021年8月14日,美国宇航局载人航天负责人凯西·卢德斯 (Kathy Lueders) 在推特上回应称:“包括Serina Maria Auñón-Chancellor在内的NASA宇航员都非常受人尊敬,为国家服务,并为该机构做出了宝贵的贡献。我们支持Serena和她的职业行为。我们认为这些指控没有任何可信度。”
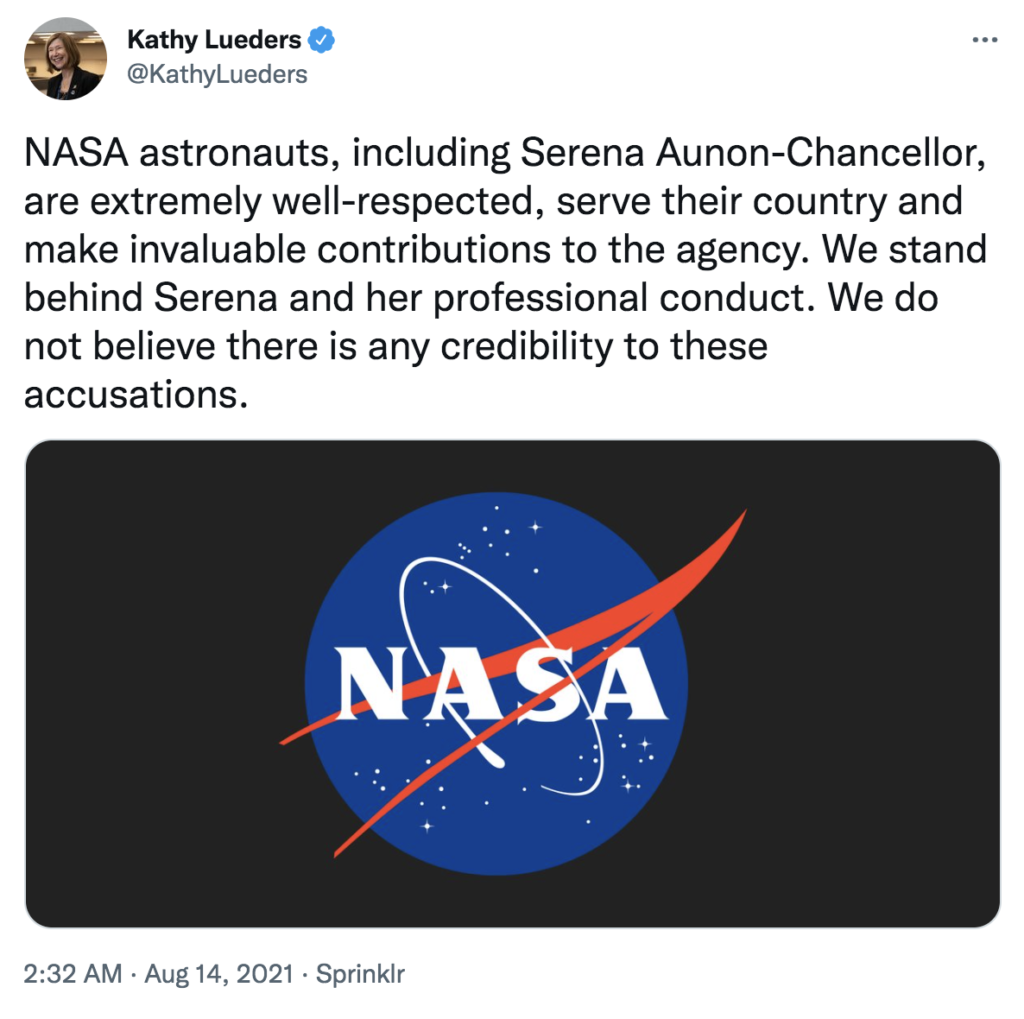
美国宇航局局长比尔·纳尔逊也表示:“我完全支持Serena,并支持我们所有的宇航员。”
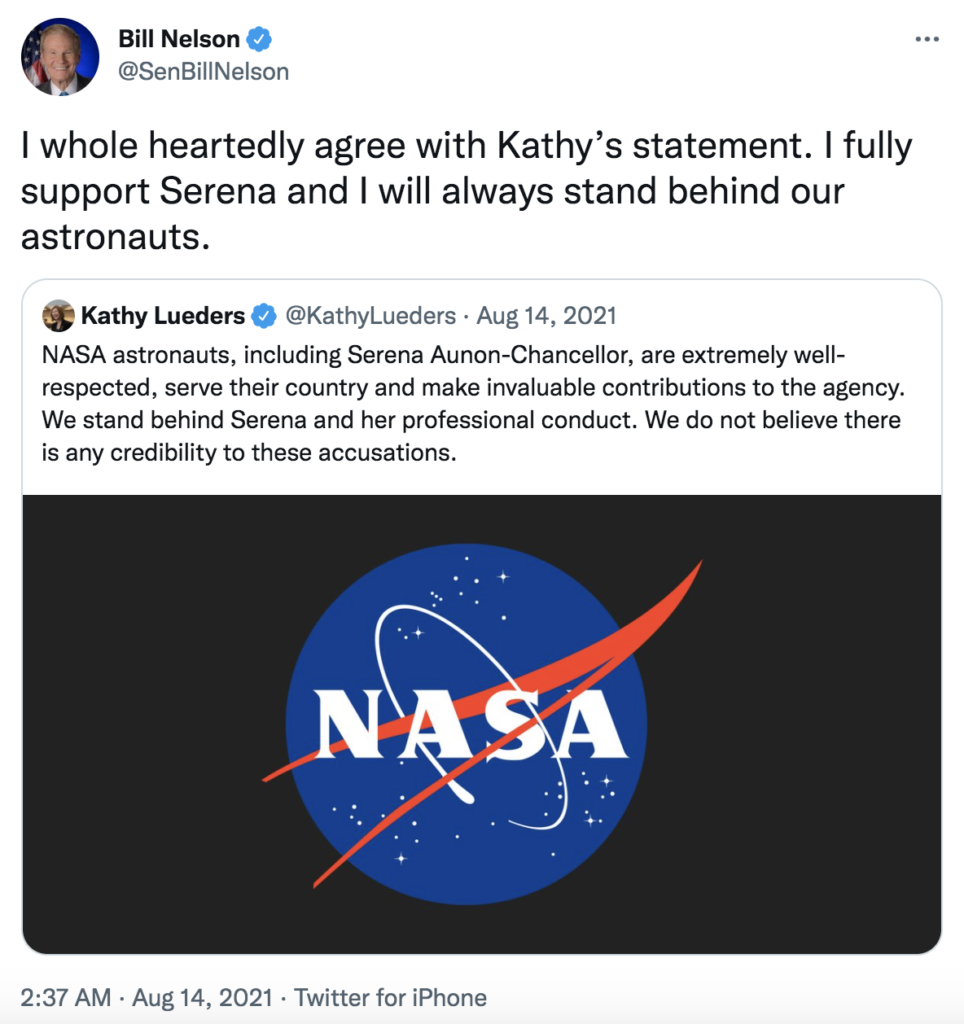
塔斯社的文章声称,事发当时,空间站俄罗斯和美国段交界处的摄像机没有工作;美国人拒绝进行测谎检查,而俄罗斯宇航员则被测谎;俄罗斯从来没有机会研究国际空间站上的工具和钻头,看看是否有任何来自俄罗斯飞船船体轨道舱的金属屑的迹象。
不过,据俄罗斯国家通讯社俄新社2021年11月26日报道,2018年12月,国际空间站的宇航员进行了太空行走,在此期间,他们打开了联盟号的外壳,并从航天器的实用隔间表面采集了拭子和样本,这些样本被送回地球接受专家和调查人员的分析。
space.com的文章认为,空间站有监控设备,美国宇航局官员在泄漏发生之前和泄漏开始时就知道美国宇航员的确切位置。视频片段显示,空间站上的美国宇航员中没有人靠近联盟号飞船停靠的俄罗斯部分。
塔斯社的文章还认为:这种损坏不可能发生在地球上,因为飞船在发射前要经过一个真空室。如果上面有任何孔洞,那么这艘船的压力会立即下降,无法通过相应的测试。八个孔中只有一个完全穿过了船体。其他的是钻头的跳动,这表明(这个洞孔)在没有必要支撑的情况下,在失重条件下进行钻探。有一个孔是在框架(船体的横向支架)上钻的,也就是说,钻孔的人没有接受过联盟号的建造培训。
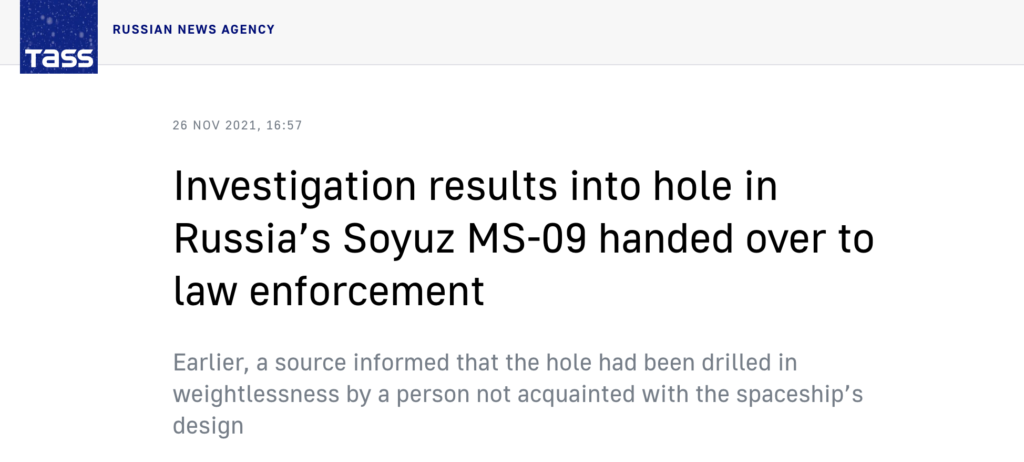
space.com的文章则认为,问题可能发生在地球上,很可能是技术人员不小心损坏了联盟号飞船,然后试图用临时补丁来掩盖错误。当空间站绕地球运行时,在反复暴露于极端温差下后,该补丁可能会在飞行期间或在轨时间脱落。
有据当时给出的核查结论是“片面”,除了考虑到风险因素,技术层面的主要考量是:简体中文网络流传的“美国宇航员为早日返回地球制造事故”的说法只是“片面”引用俄罗斯方面的陈述,而并无美方主张与回应。
不过,核查文章发表后引起争议。有读者发来反馈,不同意我们最初得出的“片面”结论:
“本报告的标题为《美国宇航员为早日返回地球制造事故?》,结论为‘片面’。 目前所有对美国宇航员 Auñón-Chancellor 的指控都来俄国的国家媒体、国营公司以及国家部门,缺乏直接证据、间接证据,只存在基于Auñón-Chancellor生理疾病方面的有限怀疑以及基于此做出的推断。俄方在两国飞船交接处的摄像头无法证明美国宇航员的非法闯入,相反,美方的监控录像可以为所有美国宇航员提供事件发生前的不在场证明;只是俄方不愿意相信 (Kotov, 2021; Thompson, 2021)。在这种情况下,握有证据的一方明显更为有利。
所以我认为,该报告所能呈现出的结论不能够反映‘片面’,而是:
• 采纳美国的‘监控录像说’,认为美国宇航员并没有非法闯入,结论为‘虚假’;
• 认为美方的监控录像‘经过修改’,但又因俄方拿不出直接、间接证据,现阶段也无第三方机构进行评判,而定结论为‘无法证实’。”
我们认真讨论了读者意见,并且重新检视了已有的证据和材料,将核查结果更改为“无法证实”。
更改的考量是:空间站有监控设备,美国宇航局官员在泄漏发生之前和泄漏开始时就知道美国宇航员的确切位置。视频片段显示,空间站上的美国宇航员中没有人靠近联盟号飞船停靠的俄罗斯部分;不过俄方声称空间站俄罗斯和美国段交界处的摄像机没有工作;现阶段也无第三方机构进行确证,故修改核查结论为“无法证实”。(参考阅读:美国宇航员为早日返回地球制造事故?)

争议案例2:
2020年9月,美国总统大选竞选期间,有微博用户发布了一条博文,声称拜登表态自己如果当选总统,将在外交方面采取一系列和特朗普不同的政策,一共涉及5点:“拜登的外交政策与川普不同,他说当选就:1,改变川普对中国产品征税政策、恢复到之前;2,称赞中国崛起是和平的、有建设性;3,改变川普制裁共产古巴政策;4,恢复伊朗核协议(默许其发展核武);5,金援巴勒斯坦(奥巴马曾给上亿;川普上任就取消)。”
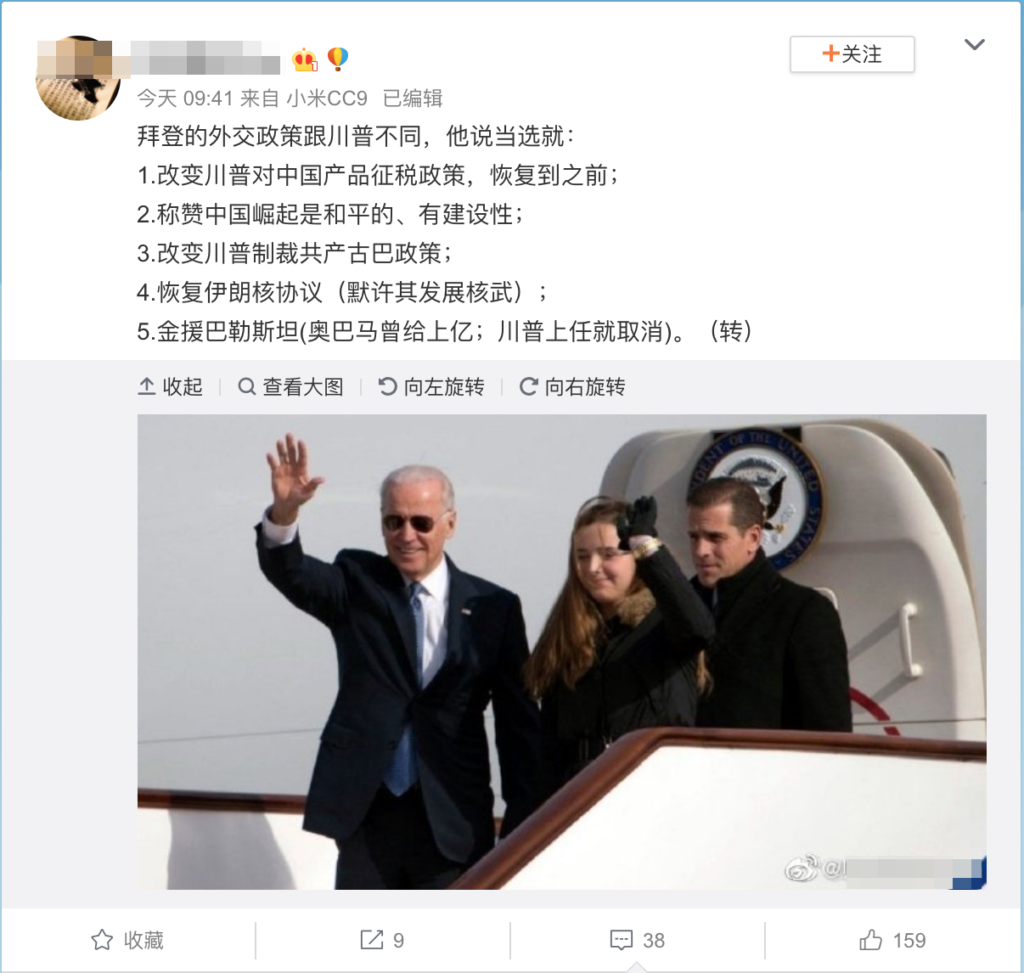
核查员针对这5个说法逐一进行了核查,得出的结论是:
1,拜登在一次采访中的指向不明的回答确实被解读为他当选后会改变特朗普对中国商品加征关税的政策,不过其助手又否认了这一点。
2,拜登并未说过当选就称赞中国崛起是和平的、有建设性。
3,拜登确实表示过当选后就会尽力推翻特朗普的古巴政策,恢复奥巴马时代的政策。
4,拜登确实承诺在伊朗遵守有关条款的前提下重返伊朗核协议,但2015年伊朗核协议并非是默许伊朗发展核武器。
5,拜登确实表示如果当选就会恢复对巴勒斯坦的援助。
可见,流言针对拜登外交政策的5点说法中,有2点是真实的,1点有误导性,2点是假的。
最终,核查员针对这一则微博帖文得出的结果判定是“部分虚假”。

而因为标题长度的限制,这条核查内容在微信公众号上的标题是:“拜登说当选就称赞中国和平崛起,不再加关税?”,无法涵盖全部5个说法。
很多读者可能不会逐一阅读针对这5个说法的详细核查,而是浏览这个标题并注意到“部分虚假”的图标,这样会造成一个印象,即“拜登说当选就称赞中国和平崛起,不再加关税”的说法是部分虚假的,而事实上,这两个点是虚假的。(参考阅读:拜登承诺当选后就停止对华加征关税,还要称赞中国和平崛起?)
以下是全球部分事实核查机构以及互联网平台在评级系统上的应用范例,从中可以一窥评级系统的复杂性以及不同机构对于同一评级标准的不同定义:
PolitiFact的评级系统:裤子着火了
2007年,PolitiFact创办,推出了名为Truth-O-Meter的评级系统,模仿计量仪表盘的设计,为事实核查的结果提供了一个简单的视觉表现,说明一项主张的真实性。
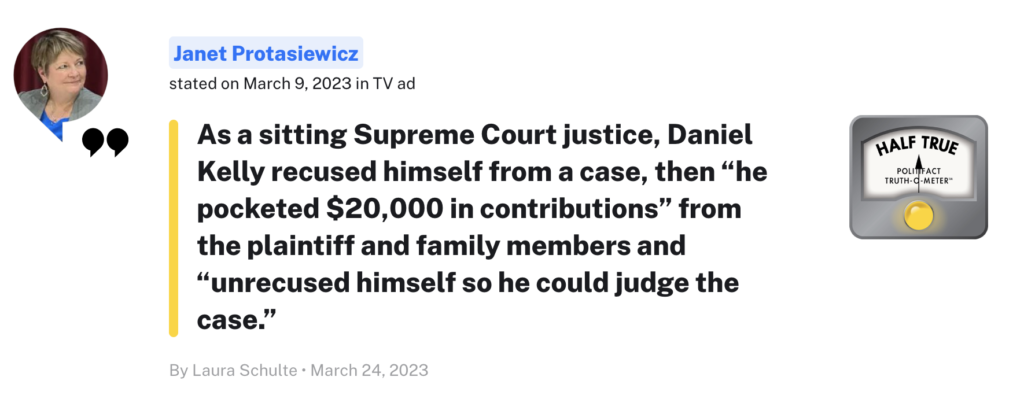
PolitiFact在官网上解释:
Truth-O-Meter评级系统的目标是反映一个说法的相对准确性。该表有六个等级,其真实性程度依次递减。
真实:陈述准确无误,没有任何重大遗漏。
大部分真实:该陈述是准确的,但需要澄清或补充信息。
部分真实:该陈述部分准确,但遗漏了重要的细节或断章取义。
大部分虚假:该陈述包含真实的成分,但忽略了可能会给人以不同印象的关键事实。
虚假:该陈述不准确。
PANTS ON FIRE:该陈述不准确,并且是一个荒谬的说法。(短语来自英语中的一首童谣:Liar, liar, pants on fire, hanging on a telephone wire.翻译成中文是:骗子骗子,裤子着火了,吊在电话线上。意思是有人在撒谎——编者注)
PolitiFact认为,举证责任在发言者身上,核查员根据有关说法发表时已知的信息对该说法进行评级。
PolitiFact还解释了评级系统的工作流程:
研究和撰写事实核查报告的记者在将报告提交给指定编辑时,会提出一个评级建议。编辑和记者一起审阅报告,通常会作出澄清并添加更多的细节。他们就评级达成一致。然后,指定编辑将已经带有评级的事实核查报告提交给另外两名编辑。
然后,三位编辑和记者通过讨论以下问题来审阅事实核查。
该陈述的字面意思是正确的吗?
是否有另一种方式来阅读该陈述?该陈述是否可以被解释?
提出这一陈述的人是否提供了证据?发言者是否证明了该陈述是真实的?
我们过去是如何处理类似陈述的?PolitiFact的判例是什么?
然后三位编辑对评级进行投票(两票决定),有时会保留记者的最初评级建议,有时会修改成不同的评级。然后会进行更多的编辑;然后发布报告。
《华盛顿邮报》的评级系统:匹诺曹的长鼻子
《华盛顿邮报》使用了说谎后鼻子会变长的匹诺曹卡通形象来标识虚假信息的严重程度,由插画师史蒂夫·麦克拉肯(Steve McCracken)绘制。
1个匹诺曹:对事实有一些遮掩。有选择地说出真相。有些遗漏和夸大其词,但没有彻头彻尾的谎言。大部分是真实的。
2个匹诺曹:存在重大的遗漏和/或夸大其词。政客通过玩弄文字游戏和使用对普通人意义不大的法律语言来制造虚假、误导性的印象。半真半假。
3个匹诺曹:重大的事实错误和/或明显的矛盾。大部分是虚假的。可能包含技术上正确的陈述,但这些陈述被断章取义,以致于非常具有误导性。
4个匹诺曹:弥天大谎
倒立匹诺曹(Upside Down Pinocchio):根据《华盛顿邮报》举的例子:美国参议院多数党领袖米奇·麦康奈尔(Mitch McConnell)抱怨说,民主党人在执政时使用了高度党派化的策略;他拒不承认自己在接管多数党时其实也这么做。
Geppetto复选标记(木匠Geppetto是匹诺曹的创造者):真实
无底线匹诺曹:2018年12月,《华盛顿邮报》称,特朗普总统重复了20多次虚假和误导性的说法,导致他们创造了一个新的匹诺曹评级——“无底线匹诺曹”(Bottomless Pinocchio)。《华盛顿邮报》事实核查员格伦·凯斯勒称:“无底线匹诺曹是指政客不但拒绝放弃已被事实核查评级为三个或四个匹诺曹的说法,反而不断重复,所以它基本上变成了虚假信息和宣传。”
Snopes的评级系统:高达19个分类
老牌事实核查机构Snopes的评级系统类目更多,达到19个。
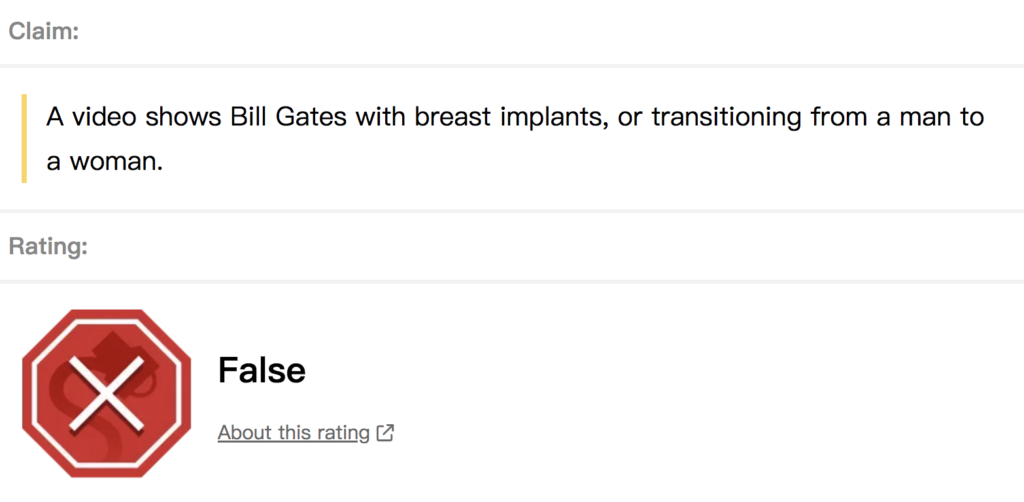
Snopes解释称:“Snopes.com上的每项事实核查都有评级,以帮助读者快速确定一个说法的可信度。读者经常问我们为什么不直接使用‘真实’或‘虚假’。”
有时,将一个话题或事件的真实性提炼成只有一个词的评级结论可能非常具有挑战性,甚至是误导性。这就是为什么我们要设置一个更广泛的评级分类。我们总是努力做到精确、准确和公平。
研究进行中(Research In Progress):这个等级指的是,对于某一说法,我们目前正在调查、但尚未得出任何可以发表的结论。
真实(True):这个等级表示一个说法的主要内容是明显真实的。
大部分真实(Mostly True):这个等级表明,一个说法的主要内容显然是真实的,但围绕该说法的一些附属细节可能是不准确的。
半真半假(Mixture):这种评级表明,一个说法具有重要的真实元素和虚假元素,以至于无法用任何其他评级来公平地描述它。
大部分虚假(Mostly False):这一评级表明,一个说法的主要内容明显是虚假的,但围绕该说法的一些附属细节可能是准确的。
虚假(False):这一评级表明,一个说法的主要内容明显是虚假的。
毫无根据(Unfounded):这个评级适用于我们已经调查过、但没有发现任何可证明的证据来支持的那些说法。这类说法通常起源于道听途说、猜测或毫无根据的谣言。
无法证实(Unproven ):这个等级适用于:我们已经检查了现有的证据,但无法得出一个真实或错误的判断,也就是说,证据是不确定的或自相矛盾的。
过期的(Outdated):这个等级适用于那些后来发生的事件使其原来的真实性等级变得无关紧要的项目(例如,作为抗议主题的某个条件已得到纠正,或者一项有争议的法律已经被废除了)。
图片/视频说明错误(Miscaptioned):这个等级用于对照片和视频的核查:照片和视频是真实的(不是部分或全部数字处理的产物),但仍然具有误导性,因为它们附有解释材料,错误地描述了它们的来源、背景和/或含义。
出处准确(Correct Attribution):这个等级表示引用的材料(讲话或文字)被正确地归属于说了这些话或写了这些文字的人。
出处错误(Misattributed):该等级表示引用的材料(讲话或文字)被错误地归属于没有说过这些话或写过这些文字的人。
传说(Legend):这个等级最常见于那些描述得非常笼统或缺乏细节的事件,它们可能在某个时间某个地方发生在某个人身上,因此基本上是无法证实的。
骗局(Scam):这个“等级”不是一个真实性等级,而是指那些已经被证实为骗局的页面。
合法(Legit):这个等级描述的是向消费者或公众提供的真实、合法的优惠或举措。
被标记为讽刺(Labelled Satire):这个等级表示一个说法是来自于它的创造者和/或更多的观众描述为讽刺的内容。并非所有被创作者或受众描述为“讽刺”的内容都构成讽刺,这个等级并不区分“真正的”讽刺和那些尽管被标记为讽刺但可能无法有效识别或理解的内容。
起源于讽刺(Originated as Satire):这个等级指的是最初来自一个被描述为讽刺的网站的内容,但后来被剥离了一些讽刺的标记,重新包装,并发布在其他地方。这个等级也适用于不一定被标记为讽刺但观众仍然认为具有讽刺意味的内容,如来自洋葱网站的内容。
召回(Recall):此等级适用于真正的产品召回公告。
消失的传说(Lost Legend):这些传说并没有真正消失,我们一直都知道它们在哪里! 我们为那些不愿意让真相妨碍一个好故事的人创建了消失的传说资料库(The Repository of Lost Legends,简称TRoLL)。
台湾事实查核中心的评级系统:
华语事实核查机构——台湾事实查核中心的评级标准有5个:



错误:讯息或新闻所传递的主要内容为错误不实,例如明显捏造虚构的传言,刻意错置时间或地点的讯息,变造或挪用影片、照片于不相干的事件,假借冠名的言论,过时讯息等。
部分错误:讯息或新闻所传递的内容为部分真实、部分错误包括:传言内容为真实,但为片面事实。传言内容确有其事,但脉络、背景有误。影片或照片包含真实影像,但掺杂不正确的背景、事件脉络等。
正确:讯息或新闻被指为错误、虚构,但经查核为真实。
事实厘清:查核中心不针对讯息或新闻的正确与否进行判断,而是整理、分析有关事件或议题的相关资讯,作为读者理解事件原委或议题本质的可信依据。
证据不足:讯息或新闻所传递的内容经查核之后,发现并无确切根据或明确事证,或所提供的事证不足以支持其宣称,但尚无其他资料足以直接否定。
社交媒体平台Meta的评级系统:
除了事实核查机构,一些大型互联网平台在事实核查方面也采取了评级制度,并且不断更新。
比如Facebook和Instagram的母公司Meta,与第三方事实核查机构合作打击平台上的虚假信息。事实核查机构可以审核和评定Facebook和Instagram上的公开帖子,包括广告、文章、照片、视频、Reels和纯文本帖子。
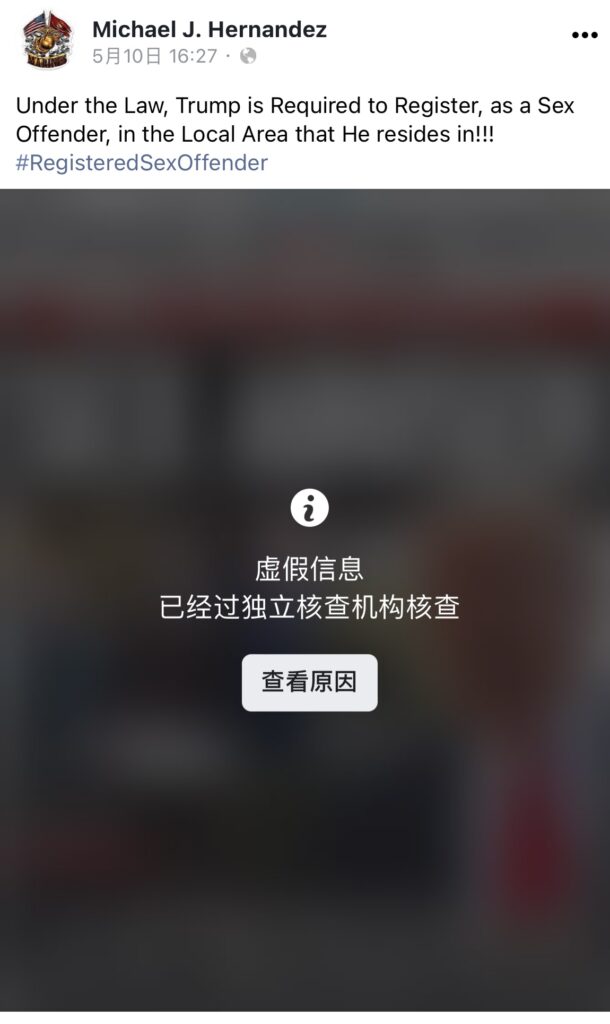
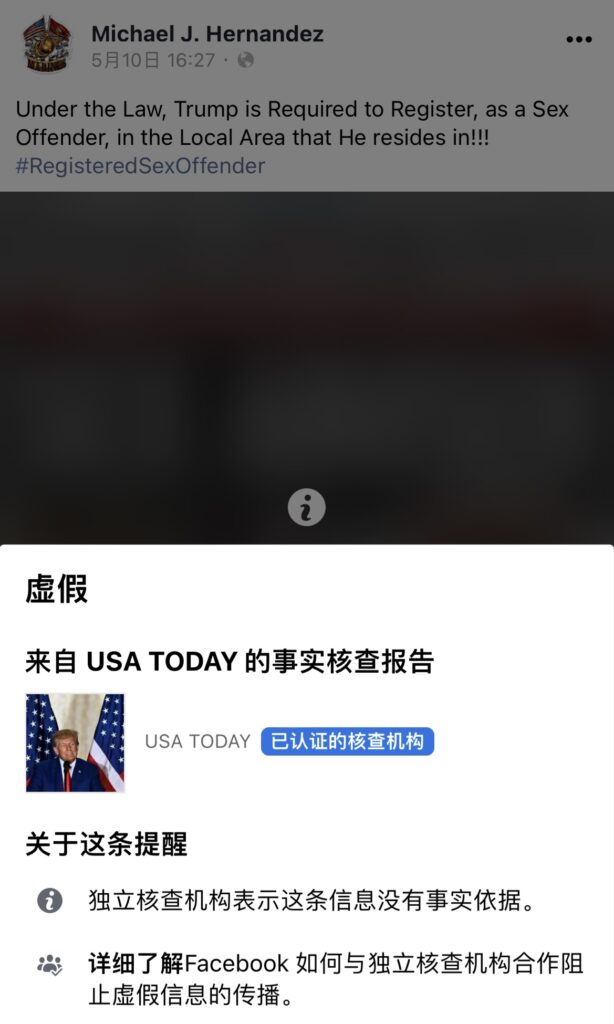
以下是Facebook官网上的评级选项,以及各项评定可能包括的内容示例。Meta负责设定这些评定准则,但最终将由事实核查机构独立审核并评定内容,而Meta不会更改评定结果。
虚假内容:
没有事实根据的内容。这类内容包括:
-虚假的引用内容。
-内容中陈述的事情不可能发生,或者不能被视为是在讲某个实际发生或说过的事情。
例如:凭空捏造一场并未发生的自然灾害。
例如:谎称某人发明了某物或获得了某物的专利。
-将事件解读为个人或团体的秘密活动的阴谋论,其中可能会引用真实或无法证实的信息,但得出的结论令人难以置信。
例如:基于不相关的高价问题声称某公司在秘密从事贩毒活动。
例如:毫无证据地声称,政府内部人员对恐怖袭击事件负有直接责任,为战争煽风点火。
-由假冒新闻机构的网站编造的内容。
-将真实存在的图片、音频或视频内容“移花接木”到某个并不相关的事件上,为该事件提供证明。
例如:使用事发前拍摄的真实照片来谎称某城镇在事件发生后并未受损。
例如:用某人认罪的真实视频来谎称另一个人认罪。
例如:当新旧条例之间存在冲突时,声称政府的旧条例为现行条例。
编辑过的内容:
使用编辑或合成手段制作的图像、音频或视频内容,作假水平远超只调整清晰度或质量,因而可能会误导用户。这一定义包括拼接内容,但不包括媒体摘录或断章截句。根据我们的社群守则,我们还会移除某些符合以下特征的编辑过的视频:是人工智能或机器学习的产物,可能会让大众误以为视频中的人说了他们本没有说过的话。这类内容包括:
-虚假、编辑过或转换过的音频、视频或照片。
例如:调整视频的速度,改变说话者的音质,试图误导他人。
例如:在真实照片中添加图像,呈现实际上从未发生过的事情。
-编辑媒体内容,从中删掉某人说的部分字词或篡改说话的顺序,颠倒原本要表达的意思。
例如:某人说的是“我不会 X”,但有心之人却将“不”字删掉了。
部分虚假
内容含有一些不实信息。这类内容包括:
-数字、日期和时间信息不准确或计算有误,但可能是在讲某个实际发生或说过的事情。
例如:谎报注册或参加活动的人数。
例如:算错政府计划所用的经费。
-关键陈述亦真亦假,但虚假内容只占一小部分。
例如:包含若干陈述的列表,其中一些为真,一些为假。
例如:包含许多关键陈述的视频,其中一些为真,一些为假。
-以观点的方式呈现,却建立在潜在虚假信息的基础之上的内容。
例如:在主张政策变更时,所提供的多条关键支持陈述中有一项可被证伪。
缺少背景信息
内容并未直接言明,而是暗示某虚假言论。这类内容包括:
-摘自真实媒体的片段或节选内容,虽然未经编辑(参见“编辑过的内容”评定规则),也未在不实背景中展示(参见“虚假内容”评定规则),但歪曲了原始内容要表达的意思,暗示了某个虚假言论。
例如:一节未经编辑的视频片段,里面有一群人在高呼他们是在和平抗议,但更完整版本的视频却显示,他们是在煽动暴力。
例如:将某人真正讲过的一些话语组合到一起,改变了此人想要表达的意思,但未达到颠倒黑白的地步。
-报道第三方提出的虚假言论时未质疑其真实性。
例如:某线人在接受电视主持人采访时做出了可被证伪的虚假断言,而主持人既未肯定也未质疑该说法的真实性。
-利用数据或统计结果暗示某个错误结论。
例如:有选择性地使用某项调研的数据来暗示该调研并未得出的某个结论。
例如:展示相关数据,暗示某项可被证伪的因果效应。
讽刺内容
内容使用了讽刺、夸张或荒谬的手法来批判某个主题(尤其是与政治、宗教或社会议题相关的主题)或提高公众对该主题的认知,但普通用户一时之间可能判断不出其中的讽刺之意。
例如,来自网站的内容未清楚打上“讽刺内容”标签或并非广为人知的讽刺内容,或者内容展示时未清楚打上“讽刺内容”标签。评定为“讽刺”的内容会添加事实核查机构的文章,为用户提供更多背景信息。
真实内容
不含有误或误导性信息的内容。